Эффективное программирование
личный блог velkin
Программирование с помощью таблиц
09.02.2021
|
velkin
 |
Мышление
В теме Обучение с помощью карточек, особенно под конец, вскрылись многие механизмы мышления. Если человек хочет что-то запомнить, а потом вспомнить, то существуют конкретные способы этого достичь. Можно так же более эффективно управлять мышлением, если понимать различие между разными видами мышления по порядку развития, такие как:
1) восприятие
2) воображение
3) словесное
4) отвлечённое
Бизнес
Возьмём для примера бизнес, подавляющее большинство использует таблицы. Раньше это был Microsoft Office Excel, в наше время многие переходят на LibreOffice Calc, что в принципе почти одно и тоже с точки зрения базового функционала. И не только для документации, для интернет магазинов тоже преимущественно предпочитают набирать данные в таблицах, а потом импортировать в CMS.
Метапрограммирование
Следующим пунктом вспоминаются системы метапрограммирования, такие как JetBrains MPS. Лично я без понятия как там всё работает, но могу провести точно такую же аналогию, где CMS соответствует системам метапрограммирования. И то и другое решение специализировано, но вот таблицы нет.
Впрочем вспомнил я об этом немного по другой причине. В JetBrains MPS решили отказаться от парсера и генерировать код в одном направлении. Я не знаю, что у них там сейчас, но что если взять таблицы и точно так же использовать генерацию в одном направлении, то есть из них в код.
Привет мир
Приступим к тестированию идеи. Лично я буду использовать Geany в качестве IDE.
print ("Привет мир!!!")Вспомним расширенную форму Бэкуса-Наура
1) Терминальные символы — это минимальные элементы грамматики, не имеющие собственной грамматической структуры.
2) Нетерминальные символы — это элементы грамматики, имеющие собственные имена и структуру.
Вид формул
| снимок экрана 01 | |
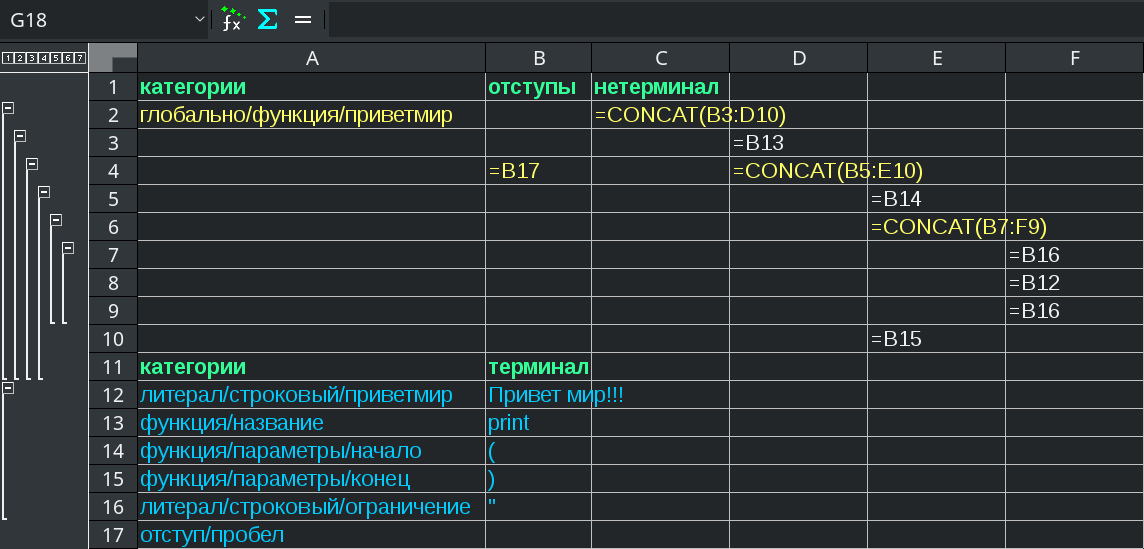 | |
категории отступы нетерминал
глобально/функция/приветмир =CONCAT(B3:D10)
=B13
=B17 =CONCAT(B5:E10)
=B14
=CONCAT(B7:F9)
=B16
=B12
=B16
=B15
категории терминал
литерал/строковый/приветмир Привет мир!!!
функция/название print
функция/параметры/начало (
функция/параметры/конец )
литерал/строковый/ограничение "
отступ/пробелВид текста
| снимок экрана 02 | |
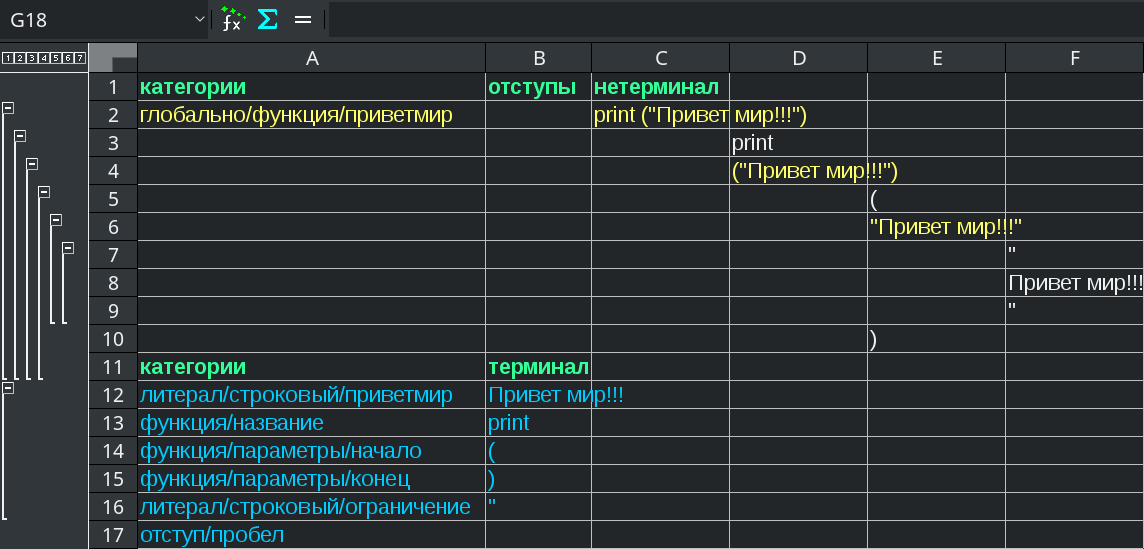 | |
категории отступы нетерминал
глобально/функция/приветмир print ("Привет мир!!!")
print
("Привет мир!!!")
(
"Привет мир!!!"
"
Привет мир!!!
"
)
категории терминал
литерал/строковый/приветмир Привет мир!!!
функция/название print
функция/параметры/начало (
функция/параметры/конец )
литерал/строковый/ограничение "
отступ/пробелЗапуск
Копирую строчку C2 в Geany в файл source.lua и запускаю.
| снимок экрана 03 | |
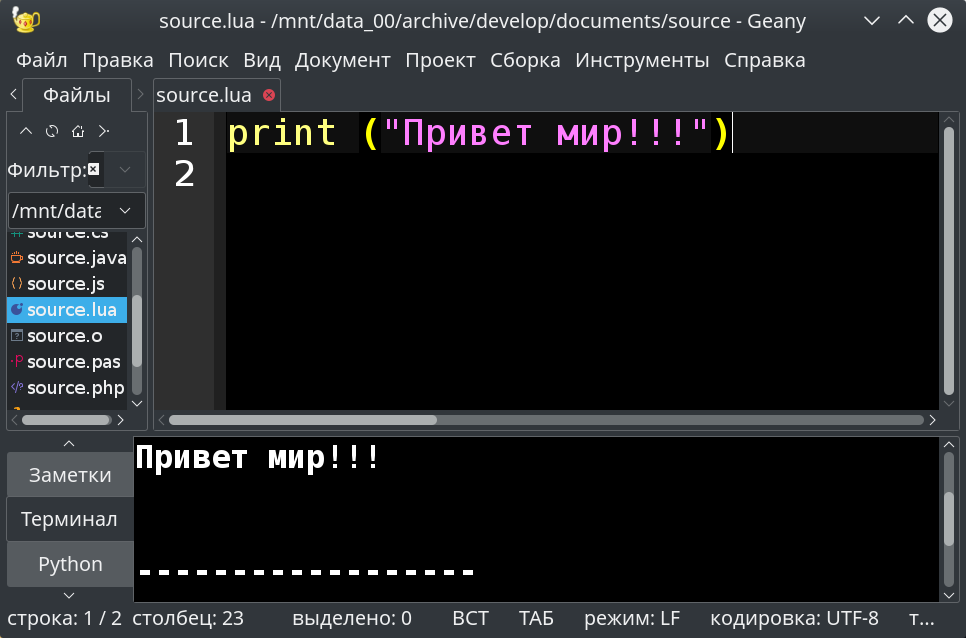 | |
Вывод в консоль:
Привет мир!!!Предназначение
Для чего нужна подобная система:
1) микроконтроль
2) метаданные
Смотри также:
1) Модифицируемость кода (Changeability QA)
2) Отсечение целей (сложность разработки)
продолжение следует...
| 09.02.2021 13 комментариев |
Вложения и отступы
Предположим нужно смещать уровни вложения, то есть перемещать ячейки влево, вправо с помощью команд вырезать и вставить.
Для этого можно использовать универсальную формулу:
Где ## это номер текущей строки в которой находится формула, а .. ячейка терминала или диапазон нетерминалов.
Так же сделан стандартный отступ от левого края уровня 1:
Хотя следует понимать, что отступы могут быть и внутри строки. Все они вынесены в столбец B чтобы сэкономить место на значимые терминалы и нетерминалы, отсюда и усложнение формул.
Вид формул
Вид текста
Запуск
Копирую строчку C2 в Geany в файл source.lua и запускаю программу:
Вывод в консоль:
продолжение следует...
Прототипирование интерфейсов
1) Создаю новый лист, для примера назову его lua.сетка.
2) Выставляю ширину и высоту всех ячеек в 0,45 см.
3) Набираю литералы на старом листе lua.
4) Создаю линейку 24x18 на листе lua.сетка.
5) Объединяю ячейки (у меня ручная настройка сочетаний клавиш)
ctrl+shift+a объединить ячейки
ctrl+shift+s разъединить ячейки
6) Добавляю формулы русской версии и дублирую таблицу для английской версии.
7) И наконец текстовый вид
Стоит отметить, что этот метод хорош тем, что благодаря одинаковой ширине и высоте ячеек можно легко дублировать интерфейсы. И понятное дело изменение нетерминалов, или если нужно даже терминалов сменит текст.
Диапазон того же меню не обязательно держать на листе lua.сетка, можно сложить нетерминал подобно программе и дать на него ссылку. Да и в принципе здесь рассмотрен лишь простейший случай без амперсандов и прочего, но принцип от этого не изменится.
продолжение следует...
Коллега, а можно, в общих чертах, так сказать, крупными мазками намекнуть: а какую проблему ты решаешь?
Мне показалось он её пока что создаёт. Решать будет позже, надо ждать следующего топика.
DO>Коллега, а можно, в общих чертах, так сказать, крупными мазками намекнуть: а какую проблему ты решаешь?
С помощью метаданных можно управлять изменениями в коде. Например, есть функционал (features) A, B, C, но он раскидан по строкам и файлам. Чтобы добавить конкретный функционал C, нужно внедрить его внутрь строк или вставить несколько строчек в разные файлы, и так же обратная операция удалить функционал. Тоже самое касается, если нужно посмотреть или изменить код. По сути это классический CRUD. Но я же не зря начал с темы про мышление, ведь изначально никак не задокументировано где конкретно находится функционал A, B, C, эта информация существует лишь в голове написавшего программиста, если уже не забылась.
Или микроконтроль:
Для примера отступ между названием функцией и параметрами это не тот же самый отступ, как в других местах. Всё это определяет стиль форматирования кода. Но гораздо важнее управление самим кодом, возможность ставить ссылки. Это позволяет проводить множество операций из науки логики. К примеру, const в C++ это ключевое слово, но используется в разных конструкциях по-разному, просто авторы языка решили назвать это одинаково. Причём они назвали всё по-английски.
Или другой случай нужно выполнить операцию сравнения из науки логики между конструкциями выполняющими одно и тоже, но в разных языках или программах. Сама же работа приведённая выше это анализ, когда код разлагается в таблицу, а потом синтез, когда он собирается в нужную конструкцию. Смысл в том, чтобы не повторять терминалы или даже нетерминалы создавая код и прочие таблицы.
В конечном итоге код это не просто какой-то текст, он парсится и преобразуется в абстрактное синтаксическое дерево. Из конструкций языка можно создать собственные конструкции, но в тексте всё это никак особо не обозначено. У меня уже давно много вопросов. Например, является ли сплошной текст идеальной формой записи кода, и ответ явно нет, нежели да. Целесообразность хранения мелких деталей производства программ в голове, а не на внешнем носителе. Как работать с сильно возросшими объёмами данных, где данные это так же программы и библиотеки алгоритмов.
И я уже написал в самом начале, что бизнес при работе с данными использует таблицы, а могли бы писать сплошной текст как программисты. Может бизнесмены поголовно идиоты, они не знают, что есть редактор простого текста — являющийся высшей формой эволюции для работы с данными? Потому проверить идею таблиц совсем не повредит.
Данные
Структуры и типы данных
Чем отличается структура (строение) данных от типа данных? Если вчитаться в определения, то ничем. Если ориентироваться на реальный мир, то структура должна иметь некое взаиморасположение данных в памяти, а не только однотипную обработку. Но в итоге всё сводится к интерфейсам с помощью которых происходит управление данными, а внутреннее устройство вторично.
Опять же если взять C/C++ и некоторые другие языки, то встроенные типы это по сути машинные команды, а вот структуры это типы определяемые пользователем. Иначе говоря в высокоуровневых языках программирования и то и другое является определёнными конструкциями.
Объекты и состояния данных
При формализации некой системы гораздо удобнее пользоваться конкретными, а не абстрактными понятиями. Это значит вместо структур и типов проще ориентироваться на объекты и их состояния. Для примера, понять как работать с неким общим списком имён сложнее, чем если представить списки имён в разных состояниях, таких как пустой список имён "", или список имён с несколькими именами "Вася; Коля; Миша;".
Может быть говорить об этом несколько преждевременно до глобального разбора программ, но раз уж эта мысль пришла мне в голову, то сразу её запишу.
продолжение следует...
Управление изменениями
Переходим к более сложному примеру взятому из статьи Модифицируемость кода (Changeability QA).
Простой исходный код в котором изменениями никак не управляют.
Далее вводится понятие функционала.
И наконец одно из решений, заключающееся в установке маркеров изменений.
Сразу вылезают два очевидных недостатка:
1) Код содержит лишние данные, такие как маркеры изменений, и чем они больше, тем больше засорения.
2) Управлять изменениями нужно не только на уровне строк, но и на уровне подстрок, чего не наблюдается.
Упрощение таблицы
Произведены следующие улучшения структуры таблицы.
1) Зелёный цвет обозначает заголовки столбцов
Пример:
2) Синий цвет это строки терминальных данных
Просто данные без всяких ссылок.
3) Жёлтый цвет это строки ссылочных нетерминальных данных
Пример:
В строке располагаются ссылки на литералы. Номер строки, в данном случае 39, должен совпадать в обоих столбцах, так как есть две ссылки, на описание и на сам терминал. Комментарий должен быть всегда в одном и том же столбце, таком как B. Сама же ссылка на терминал может смещаться для удобства чтения по уровням:
Знаки доллара в номерах ячеек поставлены для того, чтобы правильно срабатывали операции с блоками ячеек:
1) Вырезать, копировать.
2) Вставить.
4) Оранжевый цвет это строки объединённых нетерминальных данных
Пока ещё думаю в каком столбце их лучше помещать: B, С и так далее.
Разобранный пример
Скачать helloworld.ods
Операции CRUD над фунционалом
Предположим у нас есть две разновидности функционала:
и ссылки на него.
Таким образом стирая все строки со ссылками на функционал "печатать/приветмир" можно его удалить, ведь новый код будет сгенерирован автоматически. Так же можно ориентироваться на эти метаданные чтобы прочитать, изменить или добавить текущий функционал.
Благодаря микроконтролю можно осуществлять массовые операции в том числе и внутри строк кода.
Управление тегами
Древовидные теги навроде
или
можно использовать для того, чтобы вкладывать один функционал, терминалы и прочее в другие.
Но что, если в код будет включён заголовочный файл для того, чтобы создать функционал, но благодаря нему будет создано несколько видов функционала. В этом случае можно применять точку с запятой для добавления нескольких тегов.
И соответственно при удалении строка включения заголовочного файла не будет удалена пока не будут удалены все теги описывающего её функционала. Такое решение это то, которое первое приходит в голову, но если у кого есть идеи лучше, пишите.
продолжение следует...
Архитектура программ
Все о ней слышали, но никто её не видел. Настало время вывести архитектуру на чистую воду.
Люди дают каждому определению своё название. Если названия нет, то и понятия нет, или по крайне мере оно не может быть представлено в словесной форме. Для того, чтобы это исправить, нужно всего лишь придумать название. Иными словами каждая архитектура должна как-то называться, например, "нисходящая процедурная" архитектура, архитектура "недетерминированной машины состояний" и так далее.
Следующий вопрос, каждая ли программа имеет архитектуру? Здесь и далее я буду считать, даже если это не чистая архитектура, а смешанная. Отсюда вытекает простой вывод, приведённая выше программа "привет мир" для языка C++ так же имеет архитектуру или может опознаваться как программа на некой архитектуре или архитектурах.
Лично я буду считать, что архитектура это конструкция проходящая через всю программу. Но при этом не нужно думать, что её можно описать с помощью функционала.
Таким образом:
Превращаются в:
Функционал имеет более высокий уровень абстракции, тогда как архитектура и нетерминалы являются конструкциями, где архитектура опять же имеет более высокий уровень абстракции по сравнению с нетерминалами.
Скачать helloworld_arch.ods
Был добавлен столбец архитектура.
Где "процедура/нисходящая" это общее название архитектуры, а "процедура/нисходящая/точкавхода" и "процедура/нисходящая/включения" элементы конструкции. По идее можно было бы убрать название архитектуры из элементов конструкции архитектуры и писать лишь "точкавхода" и "включения", так как в одной программе должна быть одна архитектура.
Между тем более сложные архитектуры могли бы иметь персонализированные элементы, такие как процедуры "процедура/приветмир", "процедура/покамир". И здесь не нужно путать функционал "приветмир" и "покамир" и общие элементы архитектуры, такие как "процедура" и другие, которые воплощают этот функционал.
Расширение метаданных
Помимо терминалов и нетерминалов воплощающие код программы добавлены метаданные для управления функционалом и архитектурой. Подумайте как ещё можно использовать возможности метаданных и напишите в комментариях.
продолжение следует...
Я ее еще в советское время читал.
LVV>А ты в принципе читал книжку Хамби Программирование таблиц решений?
LVV>Я ее еще в советское время читал.
Сейчас посмотрел, это абсолютно другое.
Вот эта таблица:
А ещё есть такая таблица:
Но у меня, особенно это видно в последней упрощённой версии, нет никакой трансляции из одного языка в другой. По факту представлен тот же самый код, то есть даже не абстрактное синтаксическое дерево, а разобранный на терминалы код, который при сложении соответствует оригиналу один в один. Лично я не нашёл как это называется, и я ни разу не встречал подобное решение с метаданными в литературе. Если кто знает, пусть напишет.
LVV>>Я ее еще в советское время читал.
V>Сейчас посмотрел, это абсолютно другое.
Дело не в трансляции, а в таблицах решений.
Очень неплохой инструмент в некоторых случаях.
V>>Сейчас посмотрел, это абсолютно другое.
LVV>Дело не в трансляции, а в таблицах решений.
LVV>Очень неплохой инструмент в некоторых случаях.
Это всё относится к потокам управления, те же операторы ветвления, машины состояний и прочее. В общем всё то, что строится на безусловном и условном переходе из машинных команд процессора.
У меня примерно такие вопросы.
1) Что представляет из себя код?
2) Нужно ли писать уже написанный кем-то код заново?
3) Почему так сложно пользоваться чужими решениями?
И я решаю задачу основываясь на следующих принципах:
1) Код остаётся в исходном виде.
2) Дублирование исключается ссылками на ячейки и диапазоны ячеек.
3) Метаданные образуют дополнительные слои описания.
Конструирование кода в ходе развития программирования переусложнено. Сделать же что-то отличное крайне проблематично, да и получим ещё один бессмысленный язык. Множество особенностей, которые якобы помогают думать на самом деле не помогают.